===============================
MobileNetV2 "First" Accelerator
===============================
This accelerator is an exploration of both accelerating MobileNetV2 and the
CFU-Playground. This document contains the notes the author made while
implementing the accelerator.
Objective
=========
Build a 1x1xN 2D convolution operation accelerator for TfLM on an FPGA that
increases performance by 100x. As well as being useful in its own right, this
accelerator will help prove the usefulness of the CFU-Playground_.
.. _CFU-Playground: https://cfu-playground.readthedocs.io/
Background
==========
The 2D Convolution operator has many parameters and is highly configurable.
However Mobile Net V1 and V2 type networks spend more than half their time
using a subset of 2D Conv functionality to perform 1x1 or "pointwise"
convolutions.
Overview
========
The accelerator will use the CFU architecture, and thus be completely driven
via the CPU. Because the CPU is mediating the accelerators access to memory,
performance is slightly less than might be achieved with a more traditional
accelerator design. On the other hand, this architecture better allows for
iterative and incremental development. The following diagram shows the main
components and shows how a single op will be processed with the accelerator in
its final form.
.. raw:: html
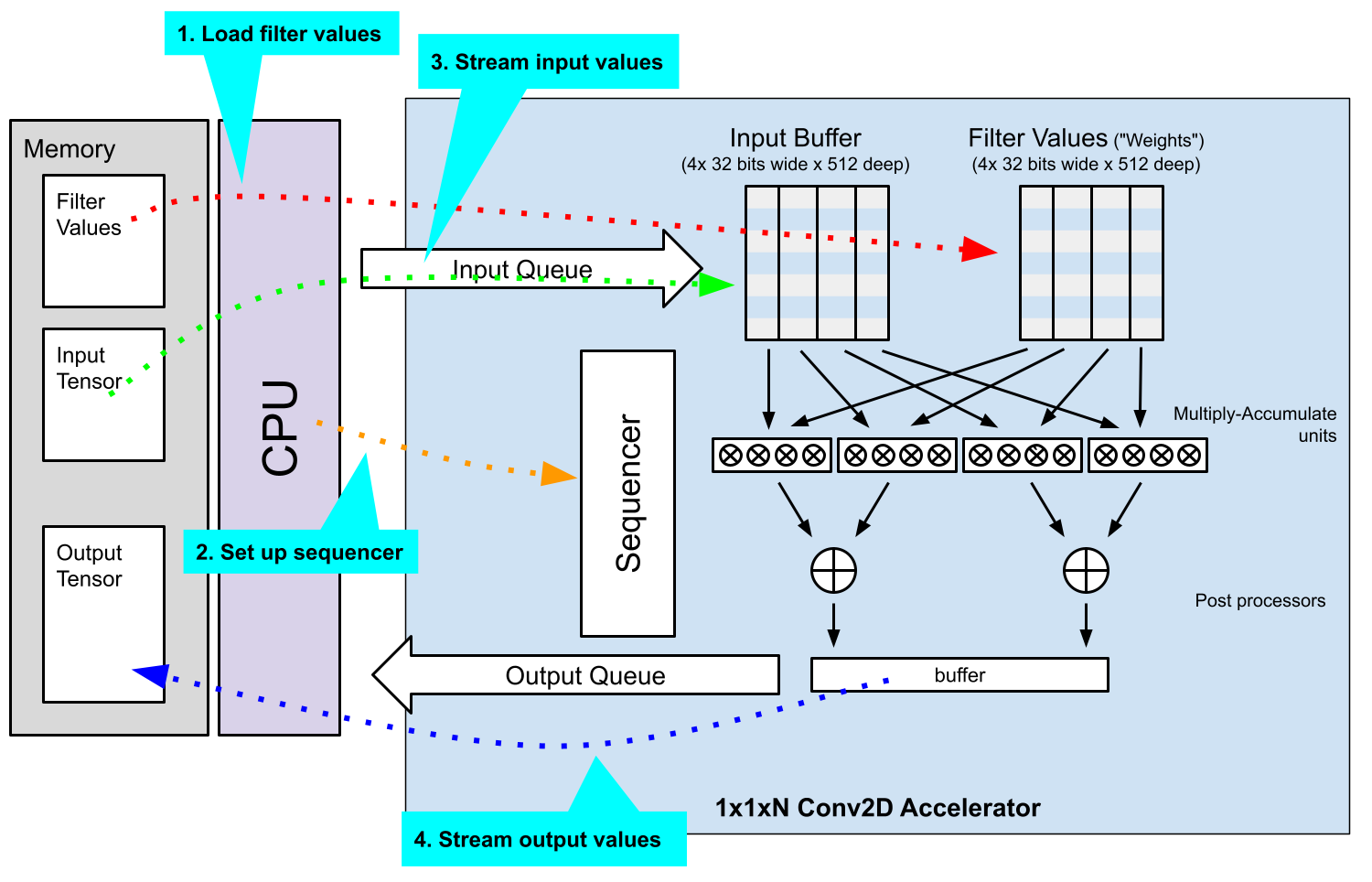 To process an op:
#. CPU loads filter values into the filter values store
#. CPU sets up sequencer to configure multiply accumulates and post processing
#. CPU streams input values from memory to accelerator via input queue
#. CPU streams output values to memory via output queue.
A Staged Approach
=================
The full design covered in the overview requires many new pieces of software to
available before it will work. Instead of trying to get there in one step,
we'll used a staged approach:
#. Investigate: profile and investigate the 2D Conv operator
#. Specialize: create a specialized C-only implementation
#. Incremental CFU: create standard CFU-style accelerator and gradually make it
more complex
#. Full Accelerator: implement the chosen design.
Investigate
===========
1x1 2D Conv Operator function
-----------------------------
In pseudocode, the 1x1 2conv operator has this form:
.. code-block:: python
for y in input_height:
for x in input_width:
for o in output_depth:
acc = 0
for i in input_depth:
acc += weights[o, i] * inputs[y, x, i]
outputs[y, x, o] = post_process(acc)
Note that:
* The number of multiply accumulate operations is
``(input_width * input_height * output_depth * input_depth)``.
* output_width and output_height are identical to input_width and input_height.
* The values of output_data at a given x,y position are dependent only on the
input_data at the same x,y position.
Profiling mnv2_first
--------------------
Model profiling and benchmarking data is recorded in the
`MobileNet V2 1x1x1Conv2D`_ spreadsheet. In summary, unaccelerated application
takes about 900M cycles, with about 95% of execution time spread across 3 types
of convolutions:
.. _`MobileNet V2 1x1x1Conv2D`: https://docs.google.com/spreadsheets/d/167Oy-KPfT9e73x6uHkTVcEXPpi0nUf67ZOAWeZY3JOY/edit#gid=0
* 63% 1x1 2D Convolution
* 22.5% Depthwise convolution
* 11% 3x3 2D Convolution
Partly because the 1x1 convolution accounts for so much execution time, and
partly because it is the simplest of the 3 operations, we chose it as the
operation to accelerate for this first project.
1x1 2D Convolution Parameters
-----------------------------
The 1x1 2D convolution uses just a subset of the possible 2D convolution parameters.
The parameters in common are:
* filter_height and filter_width = 1
* stride_width, stride_height, dilation_width_factor, dilation_height_factor = 1
* padding_width, padding_height = 0
* quantized_activation_min, quantized_activation_max = -128, 127
In addition:
* input_depth is always divisible by 8
* output_depth is always divisible by 8
* input_depth * output_depth is always divisible by 128 (8 * 8 * 2)
* all 2D convolution have per-channel bias_data
C-only Optimisations
====================
By replacing constant parameters and refactoring, we were able to reduce
execution time by 40%.
The optimisation steps were:
#. In conv.cc_, use ``if`` statements to call an inline copy of the function
with constrained parameter values. In particular, by ensuring
``filter_width`` and ``filter_height`` are ``1``, the compiler is able to
eliminate several loops.
#. In the interal copy of the function, replace constant parameters with
literal values and refactor.
.. _conv.cc: https://github.com/google/CFU-Playground/blob/main/proj/mnv2_first/src/tensorflow/lite/kernels/internal/reference/integer_ops/conv.cc#L73
Replacing Post Processing
=========================
For the next step, we replace the post-processing with gateware. The post-processing code takes the variable "acc" - the result of multiply accumulate operations, and subjects it to various arithmetic operations.
.. code-block:: c++
acc += bias_data[out_channel];
acc = MultiplyByQuantizedMultiplier(
acc, output_multiplier[out_channel], output_shift[out_channel]);
acc += output_offset;
acc = std::max(acc, output_activation_min);
acc = std::min(acc, output_activation_max);
output_data[Offset(output_shape, batch, out_y, out_x, out_channel)] =
static_cast(acc);
The parameters to this operation are:
* per output-channel parameters:
* bias
* multiplier
* shift
* per operation parameters
* output_activation_min and max
* output_offset
Post Processing Accelerator Design
----------------------------------
We will build a small accelerator where per-output channel params are stored in EBRAMs.
Testing
-------
The key arithmetic operation, MultiplyByQuantizedMultipler is non-trivial. We therefore test by:
* implementing in gateware incrementally, and making CFU instructions available
to test operations. For example `do_rdbpot_test() ` tests the
Rounding Divide By Power Of Two functionality.
* capturing a whole model layer's inputs and outputs and comparing (see
golden_op_tests.cc_)
.. _rdbpot: https://github.com/google/CFU-Playground/blob/ff0cddabd2a8e756a9d967184aac72a2c49bfefb/proj/mnv2_first/src/proj_menu.c#L103
.. _golden_op_tests.cc: https://github.com/google/CFU-Playground/blob/1198d2df4d49ce0054525648f4bc72bf9c45a30d/proj/mnv2_first/src/golden_op_tests.cc#L1302
Result
------
By moving post-processing into gateware, we were able to save approximately
47.8M cycles. Given that there are 870,600 outputs from 1x1xN convolutions,
this means a saving of about 55 cycles per output.
Moving Filter Values and Input Values to the CFU
================================================
To enable building a 16 value x 16 value accelerator, we need to move the
filter and input data values into the CFU. As a stepping stone, we will allow
the moving of these values into the CFU, with instructions to retrieve them.
Development
-----------
We proceeded by first by moving filter values into the CFU, then input values. For each, we followed this flow:
1. Define software versions of the instructions in software_cfu.c_ and update
mnv2_conv.cc_.
2. Iterate, fixing bugs. The change in program structure led to any bugs. Most
were able to be found through using the golden_op_tests.cc and many printfs.
Some sources of bugs were:
* change of pointer type from ``int8_t*`` to ``uint32*`` led to some pointer
arithmetic errors.
* attempting to do too much in a single step, resulting in bugs and
confusion. Small changes yielded better results, more quickly.
* incomplete design. One example was discovering the need for the
CFU_MARK_INPUT_READ_FINISHED() instruction to indicate when a read buffer
has been finished with.
3. Run the golden mnv2 tests to show functionality of the ops was unchanged.
4. Build gatware for the CFU, including unitests, to match the instructions in software_cfu.c
5. Enable accelerator instructions in the Makefile.
.. _software_cfu.c: https://github.com/google/CFU-Playground/blob/e99ea214abadca62ad02a825954abe0b3467211d/proj/mnv2_first/src/software_cfu.c
.. _mnv2_conv.cc: https://github.com/google/CFU-Playground/blob/f22c3fc8c82dd8190234ae89d1b04a9457371877/proj/mnv2_first/src/software_cfu.c#L87
Interestingly, the most time was spent in step 2, iterating on the C code and finding bugs at that level.
Result
------
Moving filter values into the CFU resulted in a small speed improvement -
approximately 2 cycles/MACC. However moving input values into CFU cost
approximately 2 cycles/MACC. Since the CFU stores values by word instead of
byte, the CPU must perform bit shifts and sign extensions to use values
retrieved from the CFU. This seems to be the major source of slow down. Speed
up comes from reduced memory access and consequent better data cache behaviour.
Use buffers with MACC instruction
=================================
The next step is to build a 4x4 hardware MACC. We did this in several steps:
#. Make a MACC instruction that has explicit input parameters.
#. Change the MACC to pull its input parameters from the buffers we constructed
previously.
#. Move the whole inner accumulation loop into the CFU.
Result
------
These changes together get us from 8-10 cycles per MACC down to less than 1
cycle per MACC.
Examining MACC efficiency and overhead
======================================
After moving the inner loop into the CFU 1x1 Conv2D's now take about 21M cycles
to execute 22M MACCs. Given that the accelerator execute 4MACCs per cycles,
(21M - 22M/4 =) 16M cycles are unaccounted for. Measuring what's going on
gives us:
+---------+--------+--------+---------+--------------------------------------+
| Counter | Total | Starts | Average | Raw | Notes |
+=========+========+========+=========+==============+=======================+
| 0 | 102M | 35 | 2903k | 101603342 | All Convs |
+---------+--------+--------+---------+--------------------------------------+
| 1 | 21M | 34 | 630k | 21426463 | Accelerated Convs |
+---------+--------+--------+---------+--------------------------------------+
| 2 | 7063 | 34 | 207 | 7063 | Intepreting params |
+---------+--------+--------+---------+--------------------------------------+
| 3 | 215k | 66 | 3256 | 214917 | Loading output params |
+---------+--------+--------+---------+--------------------------------------+
| 4 | 1371k | 66 | 21k | 1370965 | Loading filters |
+---------+--------+--------+---------+--------------------------------------+
| 5 | 20M | 66 | 300k | 19814645 | Pixel Loop |
+---------+--------+--------+---------+--------------------------------------+
| 6 | 0 | 0 | n/a | | |
+---------+--------+--------+---------+--------------------------------------+
| 7 | 0 | 0 | n/a | | |
+---------+--------+--------+---------+--------------+-----------------------+
Breaking the pixel loop out into the input value loading and calculation/output
sections, shows that 3M cycles are spent loading the 152,400 input words, and
17M cycles in the output channel loop and 17M cycles are spent in the out
channel loop.
+---------+--------+--------+---------+--------------+-------------------------+
| Counter | Total | Starts | Average | Raw | Notes |
+=========+========+========+=========+==============+=========================+
| 0 | 102M | 35 | 2913k | 101939586 | |
+---------+--------+--------+---------+--------------+-------------------------+
| 1 | 22M | 34 | 640k | 21759280 | |
+---------+--------+--------+---------+--------------+-------------------------+
| 2 | 6764 | 34 | 198 | 6764 | |
+---------+--------+--------+---------+--------------+-------------------------+
| 3 | 213k | 66 | 3229 | 213156 | |
+---------+--------+--------+---------+--------------+-------------------------+
| 4 | 1369k | 66 | 21k | 1369103 | |
+---------+--------+--------+---------+--------------+-------------------------+
| 5 | 20M | 66 | 305k | 20151192 | |
+---------+--------+--------+---------+--------------+-------------------------+
| 6 | 3055k | 24000 | 127 | 3055420 | Input load loop |
+---------+--------+--------+---------+--------------+-------------------------+
| 7 | 17M | 24000 | 692 | 16626194 | Out channel loop |
+---------+--------+--------+---------+--------------+-------------------------+
The out channel loop contains the (22M/4 =) 5.5M cycles of multiplications, as
well as the majority of the overhead (16.6M-5.5M =) 11.1M cycles of overhead.
Outside the loop are the remaining (3M + 1.3M + 0.2M=) 4.5M cycles of overhead.
This represents 20% of the 22M cycle total.
There seem to be some easy wins outside of the outchannel loop.
* Batch size is always a multiple of 4, so can unroll the output parameter
loading loops.
* Loading filters takes 1.4M cycles to load 89536 words of data. The number of
words of filter data in a given batch is large - this loop can be unrolled.
* The input data loop can be unrolled a little, as its size is always a
multiple of 8. (300k cycles)
Results
-------
We reduced the "outside the loop" overheads from 4.5M cycles to (2.7M + 1.1M +
0.2M=) 4.0Mcycles with simple programmatic optimizations. To go much beyond
this may require architectural changes, such as allowing DMA from the CFU to
fill BRAMs,
+---------+--------+--------+---------+-------------+--------------------+
| Counter | Total | Starts | Average | Raw | |
+=========+========+========+=========+=============+====================+
| 0 | 101M | 35 | 2892k | 101215300| Notes |
+---------+--------+--------+---------+-------------+--------------------+
| 1 | 21M | 34 | 620k | 21084765| |
+---------+--------+--------+---------+-------------+--------------------+
| 2 | 7250 | 34 | 213 | 7250| |
+---------+--------+--------+---------+-------------+--------------------+
| 3 | 174k | 66 | 2637 | 174077| 40k saved (weights)|
+---------+--------+--------+---------+-------------+--------------------+
| 4 | 1064k | 66 | 16k | 1063959|300k saved (filters)|
+---------+--------+--------+---------+-------------+--------------------+
| 5 | 20M | 66 | 300k | 19818678| |
+---------+--------+--------+---------+-------------+--------------------+
| 6 | 2689k | 24000 | 112 | 2688616| 370k saved (inputs)|
+---------+--------+--------+---------+-------------+--------------------+
| 7 | 17M | 24000 | 694 | 16661492| |
+---------+--------+--------+---------+-------------+--------------------+
Connect Post Processing to Accumulator
======================================
In the output channel loop, we are currently calculating the accumulator (with
CFU_MACC4_RUN_1), and then retrieving it to pass to the post process
instruction, CFU_POST_PROCESS:
.. code-block:: c++
int32_t acc = CFU_MACC4_RUN_1();
int32_t out = CFU_POST_PROCESS(acc);
*(output_ptr++) = static_cast(out);
By moving the post process in to the accumulate instruction, we save at least
one cycle per output channel:
.. code-block:: c++
int32_t out = CFU_MACC4_RUN_1();
*(output_ptr++) = static_cast(out);
The recorded speed up here was 810k cycles, just under a cycle for each of the
870,600 output values. It's puzzling that there was less than a cycle per
output saved.
Calculate Output Channel by Word
================================
Currently, each MACC4_RUN_1 calculates one output channel value, and then moves
it into memory. Four of these output channel words fit into a single 32 bit
word. By calculating four per instruction, we would
A. reduce the number of instructions executed,
B. reduce the number of store instructions, and
C. allow post processing to overlap with accumulating.
By changing from MACC4_RUN_1 to MACC4_RUN_4, we saved 6.3M cycles - about 7 cycles per output value.
Stream Outputs
==============
Currently, the code looks like this:
.. code-block:: c++
for (int p = 0; p < num_pixels; p++) {
LoadInputValues(input_ptr, input_depth_words);
for (int out_channel = batch_base; out_channel < batch_end;
out_channel += 4) {
*(output_ptr++) = CFU_MACC4_RUN_4();
}
CFU_MARK_INPUT_READ_FINISHED();
}
We have a per-pixel loop where we load inputs into the CFU, then calculate
output channels in groups of four. By streaming the output from the CFU instead
of requiring explicit calls to calculate the next 4 channels, we allow
calculation to overlap with storing output, which saves a small amount of
overhead:
.. code-block:: c++
for (int p = 0; p < num_pixels; p++) {
LoadInputValues(input_ptr, input_depth_words);
CFU_MACC_RUN();
UnloadOutputValues(output_ptr, batch_end - batch_base);
output_ptr += (output_depth - batch_size) / 4;
}
However, there is a larger payoff in that we can reorganise the code so that
the CFU is able to calculate while loading inputs. We may be able to remove
most of the input loading overhead, which is 3M cycles.
.. code-block:: c++
for (int p = 0; p < num_pixels; p++) {
// Load twice on first loop, no load on last loop and once every other time.
if (p == 0) {
LoadInputValues(input_ptr, input_depth_words);
}
if (p != num_pixels - 1) {
LoadInputValues(input_ptr, input_depth_words);
}
CFU_MACC_RUN();
UnloadOutputValues(output_ptr, batch_end - batch_base);
output_ptr += (output_depth - batch_size) / 4;
}
Design
------
The CFU_MACC_RUN machinery is more complicated than the CFU_MACC4_RUN4. Here is the design in diagram form.
.. raw:: html
To process an op:
#. CPU loads filter values into the filter values store
#. CPU sets up sequencer to configure multiply accumulates and post processing
#. CPU streams input values from memory to accelerator via input queue
#. CPU streams output values to memory via output queue.
A Staged Approach
=================
The full design covered in the overview requires many new pieces of software to
available before it will work. Instead of trying to get there in one step,
we'll used a staged approach:
#. Investigate: profile and investigate the 2D Conv operator
#. Specialize: create a specialized C-only implementation
#. Incremental CFU: create standard CFU-style accelerator and gradually make it
more complex
#. Full Accelerator: implement the chosen design.
Investigate
===========
1x1 2D Conv Operator function
-----------------------------
In pseudocode, the 1x1 2conv operator has this form:
.. code-block:: python
for y in input_height:
for x in input_width:
for o in output_depth:
acc = 0
for i in input_depth:
acc += weights[o, i] * inputs[y, x, i]
outputs[y, x, o] = post_process(acc)
Note that:
* The number of multiply accumulate operations is
``(input_width * input_height * output_depth * input_depth)``.
* output_width and output_height are identical to input_width and input_height.
* The values of output_data at a given x,y position are dependent only on the
input_data at the same x,y position.
Profiling mnv2_first
--------------------
Model profiling and benchmarking data is recorded in the
`MobileNet V2 1x1x1Conv2D`_ spreadsheet. In summary, unaccelerated application
takes about 900M cycles, with about 95% of execution time spread across 3 types
of convolutions:
.. _`MobileNet V2 1x1x1Conv2D`: https://docs.google.com/spreadsheets/d/167Oy-KPfT9e73x6uHkTVcEXPpi0nUf67ZOAWeZY3JOY/edit#gid=0
* 63% 1x1 2D Convolution
* 22.5% Depthwise convolution
* 11% 3x3 2D Convolution
Partly because the 1x1 convolution accounts for so much execution time, and
partly because it is the simplest of the 3 operations, we chose it as the
operation to accelerate for this first project.
1x1 2D Convolution Parameters
-----------------------------
The 1x1 2D convolution uses just a subset of the possible 2D convolution parameters.
The parameters in common are:
* filter_height and filter_width = 1
* stride_width, stride_height, dilation_width_factor, dilation_height_factor = 1
* padding_width, padding_height = 0
* quantized_activation_min, quantized_activation_max = -128, 127
In addition:
* input_depth is always divisible by 8
* output_depth is always divisible by 8
* input_depth * output_depth is always divisible by 128 (8 * 8 * 2)
* all 2D convolution have per-channel bias_data
C-only Optimisations
====================
By replacing constant parameters and refactoring, we were able to reduce
execution time by 40%.
The optimisation steps were:
#. In conv.cc_, use ``if`` statements to call an inline copy of the function
with constrained parameter values. In particular, by ensuring
``filter_width`` and ``filter_height`` are ``1``, the compiler is able to
eliminate several loops.
#. In the interal copy of the function, replace constant parameters with
literal values and refactor.
.. _conv.cc: https://github.com/google/CFU-Playground/blob/main/proj/mnv2_first/src/tensorflow/lite/kernels/internal/reference/integer_ops/conv.cc#L73
Replacing Post Processing
=========================
For the next step, we replace the post-processing with gateware. The post-processing code takes the variable "acc" - the result of multiply accumulate operations, and subjects it to various arithmetic operations.
.. code-block:: c++
acc += bias_data[out_channel];
acc = MultiplyByQuantizedMultiplier(
acc, output_multiplier[out_channel], output_shift[out_channel]);
acc += output_offset;
acc = std::max(acc, output_activation_min);
acc = std::min(acc, output_activation_max);
output_data[Offset(output_shape, batch, out_y, out_x, out_channel)] =
static_cast(acc);
The parameters to this operation are:
* per output-channel parameters:
* bias
* multiplier
* shift
* per operation parameters
* output_activation_min and max
* output_offset
Post Processing Accelerator Design
----------------------------------
We will build a small accelerator where per-output channel params are stored in EBRAMs.
Testing
-------
The key arithmetic operation, MultiplyByQuantizedMultipler is non-trivial. We therefore test by:
* implementing in gateware incrementally, and making CFU instructions available
to test operations. For example `do_rdbpot_test() ` tests the
Rounding Divide By Power Of Two functionality.
* capturing a whole model layer's inputs and outputs and comparing (see
golden_op_tests.cc_)
.. _rdbpot: https://github.com/google/CFU-Playground/blob/ff0cddabd2a8e756a9d967184aac72a2c49bfefb/proj/mnv2_first/src/proj_menu.c#L103
.. _golden_op_tests.cc: https://github.com/google/CFU-Playground/blob/1198d2df4d49ce0054525648f4bc72bf9c45a30d/proj/mnv2_first/src/golden_op_tests.cc#L1302
Result
------
By moving post-processing into gateware, we were able to save approximately
47.8M cycles. Given that there are 870,600 outputs from 1x1xN convolutions,
this means a saving of about 55 cycles per output.
Moving Filter Values and Input Values to the CFU
================================================
To enable building a 16 value x 16 value accelerator, we need to move the
filter and input data values into the CFU. As a stepping stone, we will allow
the moving of these values into the CFU, with instructions to retrieve them.
Development
-----------
We proceeded by first by moving filter values into the CFU, then input values. For each, we followed this flow:
1. Define software versions of the instructions in software_cfu.c_ and update
mnv2_conv.cc_.
2. Iterate, fixing bugs. The change in program structure led to any bugs. Most
were able to be found through using the golden_op_tests.cc and many printfs.
Some sources of bugs were:
* change of pointer type from ``int8_t*`` to ``uint32*`` led to some pointer
arithmetic errors.
* attempting to do too much in a single step, resulting in bugs and
confusion. Small changes yielded better results, more quickly.
* incomplete design. One example was discovering the need for the
CFU_MARK_INPUT_READ_FINISHED() instruction to indicate when a read buffer
has been finished with.
3. Run the golden mnv2 tests to show functionality of the ops was unchanged.
4. Build gatware for the CFU, including unitests, to match the instructions in software_cfu.c
5. Enable accelerator instructions in the Makefile.
.. _software_cfu.c: https://github.com/google/CFU-Playground/blob/e99ea214abadca62ad02a825954abe0b3467211d/proj/mnv2_first/src/software_cfu.c
.. _mnv2_conv.cc: https://github.com/google/CFU-Playground/blob/f22c3fc8c82dd8190234ae89d1b04a9457371877/proj/mnv2_first/src/software_cfu.c#L87
Interestingly, the most time was spent in step 2, iterating on the C code and finding bugs at that level.
Result
------
Moving filter values into the CFU resulted in a small speed improvement -
approximately 2 cycles/MACC. However moving input values into CFU cost
approximately 2 cycles/MACC. Since the CFU stores values by word instead of
byte, the CPU must perform bit shifts and sign extensions to use values
retrieved from the CFU. This seems to be the major source of slow down. Speed
up comes from reduced memory access and consequent better data cache behaviour.
Use buffers with MACC instruction
=================================
The next step is to build a 4x4 hardware MACC. We did this in several steps:
#. Make a MACC instruction that has explicit input parameters.
#. Change the MACC to pull its input parameters from the buffers we constructed
previously.
#. Move the whole inner accumulation loop into the CFU.
Result
------
These changes together get us from 8-10 cycles per MACC down to less than 1
cycle per MACC.
Examining MACC efficiency and overhead
======================================
After moving the inner loop into the CFU 1x1 Conv2D's now take about 21M cycles
to execute 22M MACCs. Given that the accelerator execute 4MACCs per cycles,
(21M - 22M/4 =) 16M cycles are unaccounted for. Measuring what's going on
gives us:
+---------+--------+--------+---------+--------------------------------------+
| Counter | Total | Starts | Average | Raw | Notes |
+=========+========+========+=========+==============+=======================+
| 0 | 102M | 35 | 2903k | 101603342 | All Convs |
+---------+--------+--------+---------+--------------------------------------+
| 1 | 21M | 34 | 630k | 21426463 | Accelerated Convs |
+---------+--------+--------+---------+--------------------------------------+
| 2 | 7063 | 34 | 207 | 7063 | Intepreting params |
+---------+--------+--------+---------+--------------------------------------+
| 3 | 215k | 66 | 3256 | 214917 | Loading output params |
+---------+--------+--------+---------+--------------------------------------+
| 4 | 1371k | 66 | 21k | 1370965 | Loading filters |
+---------+--------+--------+---------+--------------------------------------+
| 5 | 20M | 66 | 300k | 19814645 | Pixel Loop |
+---------+--------+--------+---------+--------------------------------------+
| 6 | 0 | 0 | n/a | | |
+---------+--------+--------+---------+--------------------------------------+
| 7 | 0 | 0 | n/a | | |
+---------+--------+--------+---------+--------------+-----------------------+
Breaking the pixel loop out into the input value loading and calculation/output
sections, shows that 3M cycles are spent loading the 152,400 input words, and
17M cycles in the output channel loop and 17M cycles are spent in the out
channel loop.
+---------+--------+--------+---------+--------------+-------------------------+
| Counter | Total | Starts | Average | Raw | Notes |
+=========+========+========+=========+==============+=========================+
| 0 | 102M | 35 | 2913k | 101939586 | |
+---------+--------+--------+---------+--------------+-------------------------+
| 1 | 22M | 34 | 640k | 21759280 | |
+---------+--------+--------+---------+--------------+-------------------------+
| 2 | 6764 | 34 | 198 | 6764 | |
+---------+--------+--------+---------+--------------+-------------------------+
| 3 | 213k | 66 | 3229 | 213156 | |
+---------+--------+--------+---------+--------------+-------------------------+
| 4 | 1369k | 66 | 21k | 1369103 | |
+---------+--------+--------+---------+--------------+-------------------------+
| 5 | 20M | 66 | 305k | 20151192 | |
+---------+--------+--------+---------+--------------+-------------------------+
| 6 | 3055k | 24000 | 127 | 3055420 | Input load loop |
+---------+--------+--------+---------+--------------+-------------------------+
| 7 | 17M | 24000 | 692 | 16626194 | Out channel loop |
+---------+--------+--------+---------+--------------+-------------------------+
The out channel loop contains the (22M/4 =) 5.5M cycles of multiplications, as
well as the majority of the overhead (16.6M-5.5M =) 11.1M cycles of overhead.
Outside the loop are the remaining (3M + 1.3M + 0.2M=) 4.5M cycles of overhead.
This represents 20% of the 22M cycle total.
There seem to be some easy wins outside of the outchannel loop.
* Batch size is always a multiple of 4, so can unroll the output parameter
loading loops.
* Loading filters takes 1.4M cycles to load 89536 words of data. The number of
words of filter data in a given batch is large - this loop can be unrolled.
* The input data loop can be unrolled a little, as its size is always a
multiple of 8. (300k cycles)
Results
-------
We reduced the "outside the loop" overheads from 4.5M cycles to (2.7M + 1.1M +
0.2M=) 4.0Mcycles with simple programmatic optimizations. To go much beyond
this may require architectural changes, such as allowing DMA from the CFU to
fill BRAMs,
+---------+--------+--------+---------+-------------+--------------------+
| Counter | Total | Starts | Average | Raw | |
+=========+========+========+=========+=============+====================+
| 0 | 101M | 35 | 2892k | 101215300| Notes |
+---------+--------+--------+---------+-------------+--------------------+
| 1 | 21M | 34 | 620k | 21084765| |
+---------+--------+--------+---------+-------------+--------------------+
| 2 | 7250 | 34 | 213 | 7250| |
+---------+--------+--------+---------+-------------+--------------------+
| 3 | 174k | 66 | 2637 | 174077| 40k saved (weights)|
+---------+--------+--------+---------+-------------+--------------------+
| 4 | 1064k | 66 | 16k | 1063959|300k saved (filters)|
+---------+--------+--------+---------+-------------+--------------------+
| 5 | 20M | 66 | 300k | 19818678| |
+---------+--------+--------+---------+-------------+--------------------+
| 6 | 2689k | 24000 | 112 | 2688616| 370k saved (inputs)|
+---------+--------+--------+---------+-------------+--------------------+
| 7 | 17M | 24000 | 694 | 16661492| |
+---------+--------+--------+---------+-------------+--------------------+
Connect Post Processing to Accumulator
======================================
In the output channel loop, we are currently calculating the accumulator (with
CFU_MACC4_RUN_1), and then retrieving it to pass to the post process
instruction, CFU_POST_PROCESS:
.. code-block:: c++
int32_t acc = CFU_MACC4_RUN_1();
int32_t out = CFU_POST_PROCESS(acc);
*(output_ptr++) = static_cast(out);
By moving the post process in to the accumulate instruction, we save at least
one cycle per output channel:
.. code-block:: c++
int32_t out = CFU_MACC4_RUN_1();
*(output_ptr++) = static_cast(out);
The recorded speed up here was 810k cycles, just under a cycle for each of the
870,600 output values. It's puzzling that there was less than a cycle per
output saved.
Calculate Output Channel by Word
================================
Currently, each MACC4_RUN_1 calculates one output channel value, and then moves
it into memory. Four of these output channel words fit into a single 32 bit
word. By calculating four per instruction, we would
A. reduce the number of instructions executed,
B. reduce the number of store instructions, and
C. allow post processing to overlap with accumulating.
By changing from MACC4_RUN_1 to MACC4_RUN_4, we saved 6.3M cycles - about 7 cycles per output value.
Stream Outputs
==============
Currently, the code looks like this:
.. code-block:: c++
for (int p = 0; p < num_pixels; p++) {
LoadInputValues(input_ptr, input_depth_words);
for (int out_channel = batch_base; out_channel < batch_end;
out_channel += 4) {
*(output_ptr++) = CFU_MACC4_RUN_4();
}
CFU_MARK_INPUT_READ_FINISHED();
}
We have a per-pixel loop where we load inputs into the CFU, then calculate
output channels in groups of four. By streaming the output from the CFU instead
of requiring explicit calls to calculate the next 4 channels, we allow
calculation to overlap with storing output, which saves a small amount of
overhead:
.. code-block:: c++
for (int p = 0; p < num_pixels; p++) {
LoadInputValues(input_ptr, input_depth_words);
CFU_MACC_RUN();
UnloadOutputValues(output_ptr, batch_end - batch_base);
output_ptr += (output_depth - batch_size) / 4;
}
However, there is a larger payoff in that we can reorganise the code so that
the CFU is able to calculate while loading inputs. We may be able to remove
most of the input loading overhead, which is 3M cycles.
.. code-block:: c++
for (int p = 0; p < num_pixels; p++) {
// Load twice on first loop, no load on last loop and once every other time.
if (p == 0) {
LoadInputValues(input_ptr, input_depth_words);
}
if (p != num_pixels - 1) {
LoadInputValues(input_ptr, input_depth_words);
}
CFU_MACC_RUN();
UnloadOutputValues(output_ptr, batch_end - batch_base);
output_ptr += (output_depth - batch_size) / 4;
}
Design
------
The CFU_MACC_RUN machinery is more complicated than the CFU_MACC4_RUN4. Here is the design in diagram form.
.. raw:: html
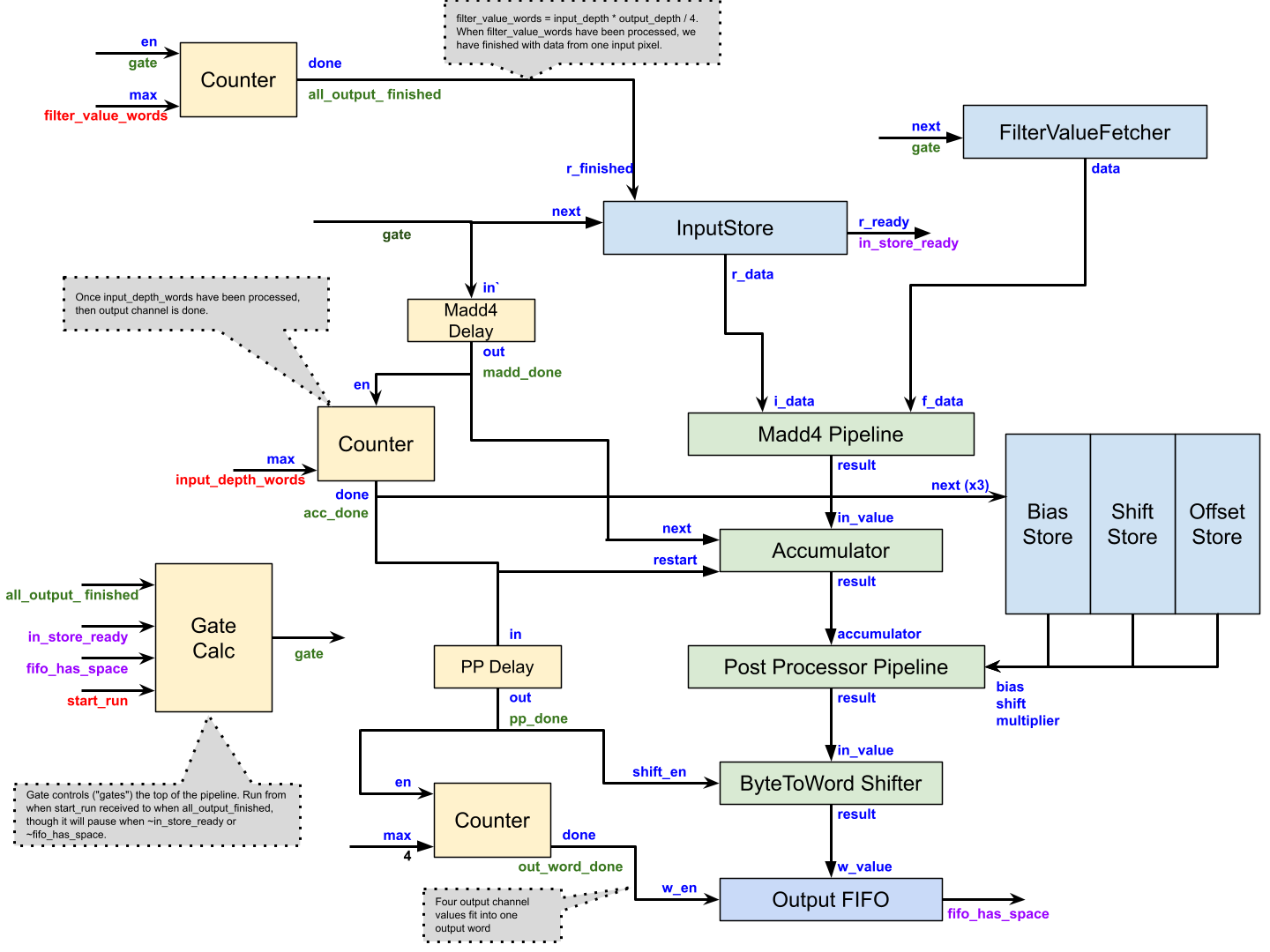 The design consists of three parts:
1. Storage (InputStore, Filter Value Store, Bias, Shift and Offset stores and the output FIFO)
2., Calculation (Madd4Pipeline, Accumulator, Post Processor Pipeline and ByteTo Word Shifter)
3. Control (the remainder of the boxes on the left).
The key signal in the control portion is "gate". When gate is on, data is being
fed into the pipeline. Gate is turned on by the CFU_MACC_RUN instruction and
turned off at the end of the run. It may also be turned off if the input store
is not ready for reading, or the output FIFO does not have sufficient room.
Results
-------
With both output queue and overlapping input, we obtained approximately 3M
cycles, or 3.4 cycles per output value.
The design consists of three parts:
1. Storage (InputStore, Filter Value Store, Bias, Shift and Offset stores and the output FIFO)
2., Calculation (Madd4Pipeline, Accumulator, Post Processor Pipeline and ByteTo Word Shifter)
3. Control (the remainder of the boxes on the left).
The key signal in the control portion is "gate". When gate is on, data is being
fed into the pipeline. Gate is turned on by the CFU_MACC_RUN instruction and
turned off at the end of the run. It may also be turned off if the input store
is not ready for reading, or the output FIFO does not have sufficient room.
Results
-------
With both output queue and overlapping input, we obtained approximately 3M
cycles, or 3.4 cycles per output value.